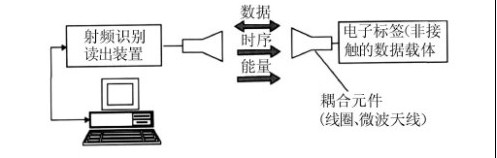
开发基于自然语言的语音识别系统面临许多技术挑战,包括使用精确的语音识别引擎将机器听到的内容翻译成文字—以及一个综合的自然语言处理器,它能判断所说内容的意思或意图,然后返回一个有意义的响应或动作。这些课题已经被广泛研究几十年了,这里不作过多讨论。本文主要讨论在远场语音接口系统中经常被忽视但同样很重要的技术性挑战:在语音到达语音识别引擎之前的语音预处理。
即使是最现代的语音识别引擎要想运转良好也有一个基本的要求—输入到该引擎的必须是语音。虽然对远场语音接口系统来说这似乎是显而易见的要求,但它却是最具挑战性的要求之一。这里的“远场”指的是用户话音距产品麦克风的距离超过半米的系统。举例来说,靠近用户脸部的智能手机形成的是一种“近场”用例,但对着一臂之长的PC机或平板电脑讲话或隔着房间对电视机、立体声系统、灯光开关、自动调温器或智能家庭控制器讲话ADC都算作“远场”用例。
近场和远场用例之间存在着许多重要的差别,这些差别产生了在近场系统中没有但在远场系统中十分艰巨的技术性挑战。
1.大动态范围:在远场系统中,用户语音可能非常低,因为他/她与产品麦克风有数米距离,但干扰可能非常大,比如在受语音控制的扬声器系统中有音乐回放的场合。
2.低信噪比(SNR)、低直接路径与混响路径比(DRR)以及未知方向的语音和噪声:远场系统中的语音噪声比要比近场系统中的小得多。随着用户不断远离产品的麦克风,语音电平会越来越小,而背景噪声电平保持不变。
同样,从用户嘴巴到麦克风的间接路径——从沿途的墙体和窗户等表面的反射路径与从用户到麦克风的直接路径相比可能有很显著的功率(即低的DRR)。在使用传统的语音处理技术和语音识别引擎时这种混响效应会造成很大的问题。
最后,在远场系统中,用户语音相对于麦克风的方向以及噪声相对于麦克风的方向都是未知的。在典型应用场合,噪声甚至与用户语音来自相同的方向。
3.全双工话音交互:在许多远场系统中,当用户对着产品讲话时,产品的扬声器中可能正在播放音频内容,如音乐、电影或话音提示。这时需要使用一个全双工的回声消除器,以便在聆听用户语音的同时抵消掉产品的回放输出声。在回声消除器并不完全了解回放内容的系统中情况就更加复杂了。
在这些情况下,实现一个依然能够良好拾取语音的系统是一项极具挑战性的任务。本文将介绍传统方法为何无法在这些远场条件下提供可接受性能的原因,然后提出了能以极具成本效益的方法提供卓越远场性能的一种解决方案。
大动态范围
用于智能家庭设备的语音捕获系统需要支持大信号动态范围,从轻声细语到响亮的音频内容回放。对于与用户距离大概在0.5米至3米范围内的设备来说,设备麦克风处的语音电平范围大概在75dB至44dB SPL。对于体积不大的音频回放设备来说,回放内容在设备麦克风处的SPL电平可能接近95dB。这种典型和极具挑战性的用例对设备中的麦克风和模数转换器(ADC)的选型有很大的影响。
对于远场应用来说,选择具有高信噪比值的麦克风非常重要。如上所述,目标语音信号的SPL 电平可能低至44dB。对于94dB SPL的1kHz音来说,如果使用信噪比(SNR)为66dB的麦克风,等效的本底噪声为28dB SPL,那么最差情况下的语音与麦克风自身噪声之比为16dB。如果选择信噪比为55dB的麦克风,那么语音与麦克风自身噪声之比可能低至5dB!
ADC内部的本底噪声也很重要,因为如果应用中的ADC动态范围不够的话,还会造成信号饱和。
图 1显示了两种ADC的输入参考噪声,它们都是麦克风增强设置值的函数。红线显示的是动态范围大约是96dB的18位ADC性能,蓝线显示的是动态范围大约为106dB的24位ADC性能。作为参考,灰线显示的是信噪比为66dB、灵敏度为-43dBV/Pascal的麦克风自身噪声电平。

图1:麦克风自身的噪声和来自ADC的噪声将叠加在一起形成系统总的本底噪声。
图 2和图3显示了分别使用96dB动态范围和106dB动态范围的ADC时系统的属性。106dB ADC可以提供更低的本底噪声和更高的饱和点。合理的设置是针对96dB ADC使用24dB的麦克风增强值、针对106dB ADC使用12dB的麦克风增强值。在本例中,使用106dB ADC时的本底噪声要低2dB,饱和点要高12dB。本底噪声低2dB对于拾取远场条件中的语音来说尤其重要。

图2:这张表显示了使用96dB ADC时的系统属性。

图3:这张表显示了使用106dB ADC时的系统属性。
考虑到峰值内容和谐振等因素,由于回声而在麦克风处产生的SPL电平可能达到96dB甚至更高。因此对于具有大声回放而且体积不大的设备来说,在使用 96dB或者更低动态范围的ADC时饱和问题很常见。当在实际系统中遇到这些问题时,唯一的解决方案通常是进一步降低麦克风的增强值,但这样做的同时会抬高本底噪声。在这个例子中,麦克风增强值需要减小到12dB。然而,与106dB ADC相比,这样做将使本底噪声高出4.3dB。因此我们可以知道,对远场产品来说首选的解决方案是使用具有高信噪比的麦克风和106dB或更高动态范围的ADC。
远场噪声/干扰和混响消除以及摆脱方向性约束
在智能家居远场应用中,获得鲁棒性的语音拾取的条件可以说是相当苛刻的。用户和设备之间的远距离导致了其信噪比比近场应用要低很多。远距离还会造成语音具有很低的直接路径与混响路径比值(DRR)。这个比值衡量的是直接传输到麦克风的语音信号能量与通过反射途径到达麦克风的能量的相对大小。在大多数家庭和办公室中,RT60时间一般在300ms至800ms范围内—这个时间将导致音频信号在室内来回反弹中损失掉约60dB的能量。当用户与麦克风的距离超过1米时,低的DRR值对于传统语音增强解决方案和语音识别性能来说是一个很大的问题。
噪声/干扰条件的变化也很大。系统需要能够同时处理静态干扰(也就是说频谱特性非常稳定或变化非常缓慢的信号)和非静态干扰(即频谱特性不断变化的信号)。当噪声相对稳定时,传统的单个麦克风增强方法是非常有效的。然而,当干扰变成非稳态时,这种方法就捉襟见肘了。因此为了改进现实世界条件下的语音识别性能,要求使用多麦克风方法。
传统的多麦克风增强算法,比如波束成形,通过估计一组受约束的空间滤波器来增强来自预定义空间方向的信号。图4显示了一种传统波束成形器的框图。这种波束成形器有三个主要单元:最小方差无失真响应(MVDR),阻塞矩阵(BM),自适应后置滤波器。

图4:传统波束成形器有三个主要单元:最小方差无失真响应(MVDR),阻塞矩阵(BM),自适应后置滤波器
MVDR 将以这样的一种方式将麦克风信号合成在一起:一边尝试将波束成形器的空波束指向干扰源,一边将一个波束指向目标源。对每一个独立的空波束都要求一个额外的麦克风,因此对于目标语音可能来自任何方向的智能家庭应用来说会显著增加成本。MVDR利用增强的信噪比产生对目标源的估计。然而,信号仍然可能包含相当多的残留噪声,因为它不能抵消来自与目标源相同方向的干扰,而这种情况在典型的现实世界中是很常见的,而且它也不能利用有限的麦克风数量抵消掉波束外的所有干扰。阻塞矩阵(BM)可以通过朝目标源放置波束成形器的零点来估计噪声/干扰。然而结果信号将包含目标源的残留,因为在混响条件下,由于反射(混响) 的原因目标源不是从单一方向到达麦克风的。
自适应后置滤波器的目的是从MVDR输出中消除残留噪声,从而提高信噪比。然而,所有滤波器算法都受这样一个事实的限制:在阻塞矩阵的输出中存在很强的目标源。噪声估计中的这种残留语音将导致所有后置滤波器扭曲到语音信号。随着混响的增加(DRR越来越小),这种失真的严重性也随之增加。解决这个问题的唯一方法是显著增加麦克风的数量,这种解决方案对许多消费类应用来说就变得太过昂贵了。
因此在对成本敏感的消费产品所具有的远场条件下,传统的波束成形解决方案不能提供令人满意的性能,需要新的解决方案。
理想的解决方案应该能在各种远场音频条件下提供一致的噪声抑制性能,即使是只使用两个麦克风。这样的解决方案不应对滤波解决方案提出任何严苛的约束条件,比如波束成形中的方向性约束,同时能提供良好的静止和非静止噪声抑制能力。理想的解决方案还应该隐式地建模混响效应,从而避免其性能受DDR变化显著影响这样的波束成形问题。最后,解决方案应该具有足够的鲁棒性,它可以完全不受麦克风位置和麦克风匹配的影响,从而消除对专门参数调谐的要求。
一种改进的远场解决方案实现是这样一种架构:算法中受监视/约束的部分只用于检测目的,不直接用于约束滤波器设计,而且滤波器都接受无监视方式的训练。图5 显示了基于盲源分离(BSS)的这样一种解决方案的高层结构。这种解决方案有三个主要部分:基于受监视功能的话音活动检测器(VAD),不受监视的空间滤波,不受监视的频谱滤波。

图5:这张图显示了基于盲源分离的SSP高层结构。
基于受监视功能的话音活动检测器(VAD)会对目标语音的存在进行概率测量。然后在不受监视的滤波模块中使用这个信息判断是否为噪声、干扰或目标语音源训练滤波器。在这种架构中可以使用任何合适的VAD。
系统的核心是不受监视的空间滤波(USF)—基于独立分量分析(ICA)的一种BSS算法。这种ICA算法设法建模目标源和干扰源的混合系统,并允许用线性滤波将它们分开来。在只有两个麦克风的系统中,USF将产生4个信号输出,每个麦克风2个。对每个麦克风来说,一个信号包含目标源和一些残留噪声,另一个信号包含对所有干扰源的估计,其中目标源已经被滤除。
USF做到这一点所需的唯一信息是在知道何时目标语音有效以及何时噪声有效,这个信息来自VAD。然后USF寻找滤波器以完全不受监视的方式对目标源和干扰源进行分拆。USF并不明确地使用源方向,虽然这个信息可以用来改善 VAD决策。另外,麦克风在设备上的位置和麦克风之间的不匹配对算法的影响很小。在ICA系统中,如果存在N个源,那么通常至少需要N个麦克风来恢复原始信号。然而,通过将信号看作是包含1)一个目标语音信号和一个噪声信号,或2)只有一个噪声信号,ICA可以只与两个麦克风和未知数量的噪声源一起使用。
USF 的输出不是在系统输出中直接使用,因为它假设合成信号是由有限数量的空间定位源产生的信号的线性合成。这种一致性假设条件对主要的语音源信号来只是部分成立,但对现实世界噪声来说不是的。因此线性滤波对于现实世界应用来说不是最优的,要求用非线性、随时间变化的统计性后置滤波对信号进行补偿。后置滤波方法通常涉及到对由线性滤波器输出推导出的频谱/临时模板(或增益)进行估计。虽然模板通常能提高噪声抑制能力,但如果没有考虑分拆模型不确定性的话,屏蔽效应可能导致信号的严重劣化。
用于频谱滤波的方法可以基于不受监视的频谱增益分布学习,而这种分布源自USF的输出信号。然后就能产生语音存在/不存在的概率;这些概率用来控制对每个通道的频谱增强。增强技术可以消除有害的干扰,与此同时消除最近的混响分量,即有效地去除混响。
图 6和图7显示了这样一种系统的性能例子。在这个测试中,用户距双麦克风系统3米远。麦克风处的目标语音电平是60dB,麦克风处的干扰语音电平是 50dB。图6中的上面通道显示的是没经任何处理的接收信号。下面通道显示的是经过处理后的输出。图7显示了处理之前和之后的干扰频谱内容。在这种条件下,可以达到大约30dB的干扰信号抑制。当未处理信号通过语音识别引擎发送时,可能达到95%的误字率(WER)。经过处理后的WER可下降到15%。

图6:上面通道显示的是未经任何处理的接收信号。下面通道显示的是处理后的输出。

图7:显示的是处理之前和处理之后的干扰频谱内容。
声学回音消除(AEC) 已经存在很多年了,是任何免提通信系统的必要部分。声学回音消除器可以从麦克风记录中消除设备本身正在回放的音频。最简单的AEC是半双工的,也就是说,当远端在讲话时,它会马上关闭近端的麦克风,反之亦然,即当近端讲话时则关闭远端的麦克风。在这些系统中,同一时刻只能有一边讲话。
对于语音控制应用来说,真正的全双工回音消除是系统的一个必要部分,也就是要达到语音控制和回放同时进行的效果。声学回音消除器(AEC)要想正常工作,需要能够访问到信号,也就是设备正在播放的回音参考。AEC随即使用这个回音参考对房间内的声学回音路径进行线性建模。然而在实际系统中,回音路径中通常有相当多的非线性因素,它们会显著降低系统性能—比如当设备正在试图从小的扬声器中产生大的回放音量时。另外一个例子发生在回放信号被发送到AEC作为回音参考之后对这个回放信号进行非线性的后置处理之时。语音控制的机顶盒(STB)就是这种情况,此时AEC在工作,机顶盒中也获得了回音参考,但电视机很可能在播放音频之前在音频上叠加一些未知延时和后处理。在这些条件下使用传统的AEC性能会很低。
这个问题可以这样解决:将AEC连接到前文介绍的噪声抑制技术。只要AEC能够区分远端、近端和双边谈话活动,这个信息就能用作USF的活动检测输入。这种方法在具有非线性及受损回音参考的系统中可以提供真正全双工的AEC性能。
另外,这种新的AEC技术应该包含一个延时估计算法,以便通过对齐回音参考和麦克风信号来解决回音路径中的未知延时,就象在机顶盒案例中那样。
图 8和图9显示了一个机顶盒系统的性能。用户距电视机3米远,麦克风模块位于电视机顶上,并连接到机顶盒。用户给机顶盒发出自然语言命令。在麦克风模块处目标语音的SPL是60dB,来自电视回放内容的回音SPL是72dB。图8的上部显示的是未经处理的麦克风信号,底部显示的是经过处理的麦克风信号。图9 显示的是处理前后残留回音的频谱内容。在这个案例中,处理前的误字率(WER)是100%,处理后则达到了8%。

图8:这张图的上部分显示的是未经处理的麦克风信号,下部分显示的是处理过的麦克风信号。

图9:这张图显示了处理前后残留回音的频谱内容。
本文小结
传统的波束成形语音增强方法在智能家庭远场应用环境中通常无法提供可接受的解决方案,因此很有必要开发其它的系统来成功地满足和应对这些远场挑战。举例来说,科胜讯(Conexant)公司已经开发出了如同本文所述的极具成本效益且高集成度的解决方案,这些解决方案采用了高动态范围的ADC,在低信噪比、低DDR以及语音和噪声方向未知的条件下具有卓越的远场噪声/干扰抑制性能,而且即使在回音信号不完全确定的情况下也能实现真正全双工的声学回音消除。这些解决方案已被科胜讯公司部署到从智能家庭设备到平板电脑、PC和可穿戴设备的许多产品平台上,并且所有产品都具有优秀的性能结果。
像波束成形等传统方法要求极高的麦克风成本、特殊的平台调谐,并对麦克风位置、匹配以及语音和噪声的方向性有许多约束条件。而上述替代性解决方案的鲁棒性可直接转换为更好的性能,并能在新的智能家庭产品开发和制造过程中显著节省成本。