1.引 言
人们一直梦想有朝一日可以摆脱键盘或遥控设备的束缚,拥有更为友好、亲切的人机界面,使得计算机或家用电器可以像人一样听懂人的话语,看懂人的动作,执行人们所希望的任何任务,而语音数字信号处理正是其中一项至关重要的应用技术。随着科技的发展,品种繁多的消费电子产品进入了人们的生活,利用语音技术对电子产品的控制也将是未来的消费电子的一大趋势。然而在语音通信的过程中,不可避免地会受到来自周围环境中噪声的干扰,甚至在某些极端场合下(如工地或公交车站),噪声几乎会覆盖掉全部的有用信息。这使得识别的效率急剧下降,严重时会直接导致误操作,所以在噪声背景下的语音提取及增强有重要意义[1]。
语音增强作为预处理,可以改善这些系统的性能,例如语音识别正在步入实用阶段,但目前的识别系统大都是在安静环境中工作的,在噪声环境中尤其是强噪声环境,语音识别系统的识别率将受到严重影响,这就需要语音增强技术进行预处理。所谓语音增强就是对带噪语音进行处理,改善语音质量,减少语音通信过程中噪声对语音的损害,对收听人而言主要是减少疲劳,改善语音质量,提高语音可懂度,而对语音处理系统而言则主要是提高系统的识别率和抗干扰能力。
目前国内外有关抗噪声技术的研究成果大体可分为三类。一类是采用语音增强算法,提高语音识别系统前端预处理的抗噪声能力,提高输入信号的信噪比。第二类方法是寻找稳健的耐噪声的语音特征参数并提出了短时修正的相干系数,作为语音特征参数,该参数是基于自相关函数序列的线性预测技术,实验证明,该参数对宽带语音具有较好效果。但是,目前的补偿算法通常只考虑到噪声环境是平稳的,在低信噪比语音以及非平稳噪声环境中的效果并不理想。而解决噪声问题的根本方法是实现噪声和语音的自动分离,尽管人们很早就有这种愿望,但由于技术的难度,这方面的研究进展很小。近年来,随着声场景分析技术和盲分离技术的研究发展,利用在这些领域的研究成果进行语音和噪声分离的研究取得了一些进展[2]。
耳机技术可以说是手机背景噪音抑制技术的最初解决方案,语音压扩技术现在广泛的应用在通信系统中,麦克风阵列技术有良好的抗噪性能[3],但是其目前的成本过高,期待着材料技术的突破。
本文将从硬件和软件方面综合设计语音增强的系统。本系统采用SOPC快速设计数字电路方案,在外围扩展组合麦克风以及音频输出模块,实现了整个硬件部分。通过分析现有的语音增强方案的缺点,提出了独特的语音增强方案。本系统可以根据用户的特征进行自我定制语音输出,对环境中杂乱无章的噪声采取了更为灵活的过滤方式。
2.系统总体设计
SoC(System on Chip)片上系统是现代电子系统设计的一个发展方向,它将原先分立的多个芯片集成在一块芯片上,通过提高芯片的集成度、减少系统芯片的数量和相互之间的PCB连线、减少PCB面积来降低整个系统的成本,同时使系统的性能、功能和可靠性都有很大的提高。随着新型的高性能、低成本FPGA的出现和综合技术的提高,基于FPGA的SoPC(System on Programmable Chip)可编程片上系统正逐步走向市场。基于FPGA的SoPC与基于ASIC技术的SoC相比,具有设计周期短、产品上市速度快、设计风险和设计成本低、集成度高、灵活性大、维护和升级方便、硬件缺陷修复和排除简单等优点。因此基于FPGA和包括32位CPU在内的各种IP核的系统级应用开发将是下一代电子系统设计的发展方向。
顺应这个潮流,FPGA器件的方要供应商Altera和Xilinx都推出了各自的SoPC解决方案:Nios系统和MicroBlaze系统。它们功能强大、开发环境和配套IP核完善,是工程应用的首选。但是它们只能用在各自厂商的FPGA上,不但配套IP核价格昂贵,而且用户无法获得所有源代码,不利于我国SoPC技术的发展[4]。针对这种情况,本系统使用OpenCores组织提供的各种免费、开源的IP核,构建了以OpenRISC1200CPU为核心,配以各类外围IP核的完全开源的SoPC系统。其可以运行μClinux系统。同时本系统采用的所有IP核在源代码不变的情况下可以使用Xilinx的开发工具进行综合、布线,为该系统在其他FPGA平台上的运行打下了良好的基础。
本系统总体构架如图一。冗杂声音信号经ADMP421麦克风阵列采集,由SPI控制模块读取语音信息,将声音信号采集进系统进行进一步处理。人机交互可以设置语音处理的各项初始参量,确定语音阈值,实现用户自定义的语音处理,增强系统对环境的适应性。之后,语音信息被送往FIR处理单元,进行下一步的滤波处理,初步将语音信号提取出来。这时,可以利用OR1200构建的CPU进行进一步的软件处理,以实现更为复杂的语音处理。经过相关处理的语音信号,可以直接通过MCU控制和IIS控制输出给WM8731进行音频解码输出。如果需要较大功率输出,可以使用音频放大电路将音频信号放大输出。
另外,由于FPGA内部的存储器较小,且为易失性的,所以需要外扩存储器存储程序以及用户设定信息。如果需要运行操作系统,则需要外扩RAM以保证程序执行所需存储器和提高程序执行效率。
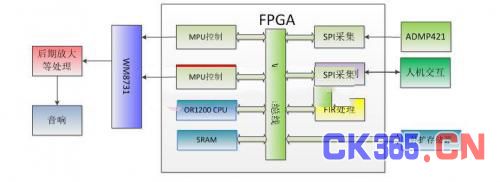
图 1 SOPC语音增强系统构架
3.单元模块设计
3.1 软核OR1200
OR1200是OpenCores组织提供的基于GPL协议的开放源代码处理器,性能介于ARM7和ARM9之间,适合一般的嵌入式系统使用。OpenCores组织提供了大量的源代码IP核供研究人员使用,OR1200在使用0.18um及6层金属工艺时,主频可以运行在300MHz,可以提供300Dhrystone、2.1MIPS和300次的32x32 DSP乘加操作。OR1200是32位标量RISC处理器,具有哈佛结构、5级整数流水线、支持MMU和Cache,带有基本的DSP功能。外部数据和地址总线采用Wishbone片上总线标准。
3.2组合麦克风
目前市面上,最为流行驻极体麦克风(ECM),但硅麦克风大有取而代之的趋势,这主要由于硅麦克风有驻极体麦克风不可比拟的优势。硅麦克风就单个器件来说,半径是驻极体麦克风的 1/3 或 1/4,尺寸大大减小,有更高的集成度。能耗为 ECM 的 1/2。不仅如此,硅麦克风有更强的抗射频干扰(RFI)和电磁干扰(EMI),可以在恶劣的电磁场环境正常工作,同时能够承受表面贴装工艺的高温度而性能不变。MEMS麦克风[5]非常适合麦克风安保和监视应用,可同时改善采集和波束成型体验。ADMP421[6]可以提供一流的SNR和扩展频率响应,音质出色,声音高度清晰,适用于高清语音/声音识别。器件间的容差极小,增强了波束成形的方向性,同时卓越的PSRR和小封装尺寸使设计人员可以极其灵活地放置麦克风。
另外ADMP421数字麦克风有着尘埃过滤器,工作性能不会随着时间的推移而下降。
ADMP421与FPGA的接口为通用的SPI串行控制方式,控制方式比较简单。
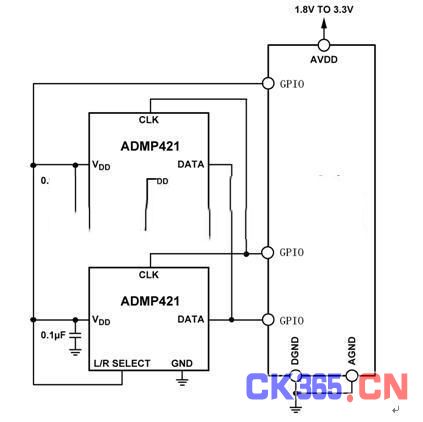
图 2 ADMP421典型接口电路[7]
3.3 WM8731音频输出模块
WM8731[8]是一款专用低功耗立体CODECs,内置了耳机驱动。该芯片是专门为MP3播放器设计的,音频采样和播放的芯片,其原理图如下:
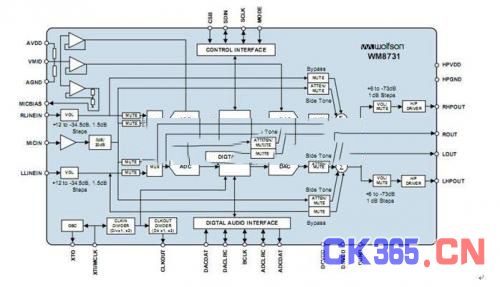
图 3 WM8731原理图[8]
该芯片支持立体声输入和播放,内置时钟发生器,支持多种时钟模式,通过一个12MHz时钟,该器件可以直接生成44.1kHz、48kHz和96kHz等采样率,以及MP3标准定义的其他采样率,完全不需要一个独立的锁相环(phase locked loop)或晶振。音频采样和播放采用24位AD和DA,控制信号可用IIC协议和SPI协议,数字音频信号输入输出可采用Right justified 、Left justified ,IIS和 DSP 四种模式。
4.1. 硬件设计
本系统使用组合麦克风得到语音信号[9]。系统将使用6个背靠背的ADMP421并使用隔音效果比较好的垫片将它们隔离,这样就可以构成简单的差动结构,差动输出的信号就可以简单的消除来自不同方向的噪声干扰。
4.2. 相位调制
由于声音信号是有一个比较宽的频率范围,大致在300Hz-3400Hz[10],虽然ADMP421体积较小,但是它们收到的声音信号相互之间还是存在着相位差的。例如,两个麦克风之间相距0.5cm,由于声音的传播速度是340m/s(室温下),那么其传播时间相差即为14.7微秒,其相对应的频率即为68K Hz。那么频率为17K Hz的信号就会因为相差90°的相位,而不能由差分的信号消除。而在别的频率的信号也会由于相位差的原因而出现不同的相减差别。在相位接近180°的情况下,甚至会出现噪声增强的现象。
所以,在本系统中,首先要进行距离匹配,使各路信号基本实现相位之间的匹配。下面给出两个具体的方案:①采用频域的分析方法,将语音信号解析,然后根据麦克风之间的距离计算相位差,之后补偿。②在数据流中加入数字滤波器,使滤波器的相频相应恰恰可以补偿相位差。前者较为精细,处理效果好,但是要耗费大量的系统资源;后者是较为通用的方案,虽然不能实现完全的匹配,但是效果还是可以接受的。
4.3用户特色语音设定
由用户预先在较为安静的环境中进行麦克风测试。用户对着主麦克风说话,然后由内部的匹配算法,将各个方向的麦克风的信号收集然后根据用户的语音信息进行合理的配置,尽量增大各个麦克风的该用户的语音特征音量输出。
之后,在噪声环境中,用户可以选择相应的配置,增大用户的特征音量,减小环境噪声。如果噪声的频率特性较用户语音的差别较大,这种方法就比较有效。
4.4其他语音滤波算法的应用
随着DSP(数字信号处理)技术的发展和在各种应用中的深入,数字信号处理算法的研究是当前的一个热点。其中自适应滤波算法以其卓越的自学习和自跟踪性能在以上的产品中得到广泛的应用,也是本文要研究的方向。自适应滤波的基本理论通过几十年的发展己日趋成熟,近十几年来自适应滤波器的研究主要针对算法与硬件实现。算法研究主要是对算法速度和精度的改进,其方法大都采用软件C、MATLAB等仿真软件对算法的建模和修正[11]。
自适应滤波算法有以下几种常见的实现方式:RLS算法,SIGN一ERROE一LMS算法,LMS算法,NLMS算法。而本系统可以根据不同的噪声背景选择,不同的消噪模式。
5.设计流程
SOC设计一般采用经典的自顶向下的设计流程。它开始于规范制定、功能划分,结束于系统集成和验证。主要包括以下步骤:① 为系统和子系统制定全面的设计规范。② 精简设计中的结构和算法。如果必要的话,包括软件设计和软硬件协同仿真。③ 把芯片功能划分为定义好了的核。④ 设计或者选择合适的核。⑤ 把核进行集成,进行功能验证和时序验证。⑥ 把子系统或系统提交给下一级更高层次的集成,如果是最顶层,则可以Tapeout(投片)⑦ 验证设计的所有方面(功能、时序等等)。
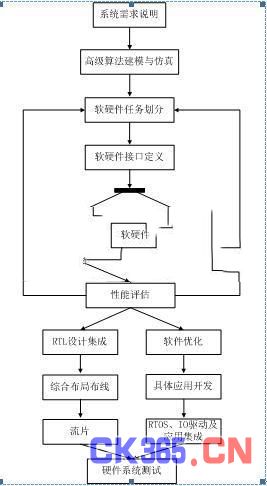
图 4 SOC设计流程
本系统做为SOPC设计方法的独特之处在于:1.高级算法建模,可以利用matlab仿真之后,使用DSPbuilder将算法生成为VHDL的硬件描述语言代码,直接在FPGA中生成电路,验证算法。相对于仿真模拟,可靠性进一步增加。2.由于采用SOPC的设计方案,在整个系统设计完成后,可以利用FPGA直接做成板级产品,投入市场。现在的低端FPGA的成本已经下降很多,对于本应用的规模电路设计,其完全可以满足需求。待市场明细后,可快速生成SOC方案,进一步降低成本,降低投资风险。
6.可行性分析
麦克风的差动结构之前就有人研究过,不过都是很简单的直接将不同方向的信号进行相减操作,未充分考率信号中的相位延迟问题。对于相位调制的方法,使用FFT硬件算法的方案已经比较成熟。
OR1200已经比较成熟。当使用0.18 m和6层金属工艺时,OR1200的主频可达300 MHz,此时可以提供300 Dhrystone 2.1 MIPS和300M 次/秒的32×32的DSP乘加操作能力[12]。OR1200在2002年9月被Flextronics公司选中,用于集成在Flextronics的设计中,并提供商业服务。2003年8月,Flextronics公司成功实现了集成OR1200、10Mbps/100Mbps自适应以太网MAC控制器、32位33MHz/66MHzPCI接口、16550兼容UART和Memory控制器的SoC芯片,并成功运行了μClinux和Linux操作系统。另外,由于OR1200是由OpenCores组织负责开发和维护、免费、开源的RISC处理器内核家族,现在其已经支持以下IP:
·Wishbone 总线互连
·CPU Debug 模块;
·通用 I /O 控制器;
·片内高速 RAM 控制器;
·16550 兼容 UART 控制器;
·Memory 控制器;
·10Mbps/100Mbps 自适应以太网 MAC 控制器;
·VGA/LCD 控制器;
·8042 兼容 PS/2 控制器。
故OR1200能满足一般的用户需求,而且其开源性将引来更多的开源IP的加入。