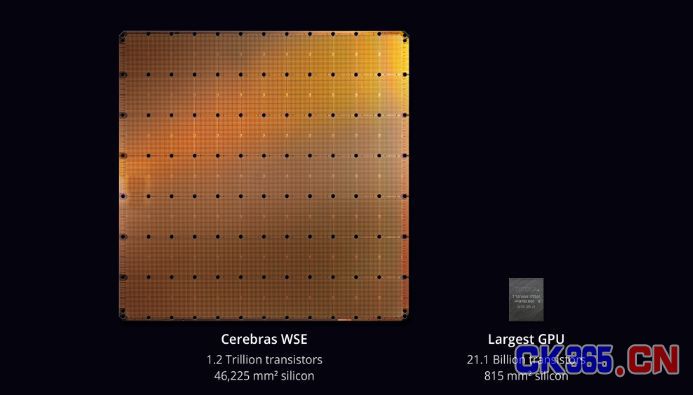
上周在斯坦福纪念礼堂举行的HotChips-31大会上,有一个令人震惊的消息。那就是是一家致力于机器学习加速器的初创公司Cerebras最终推出了一款开创性的加速器芯片。据介绍,他们在单颗die上集成了1.2万亿晶体管(46,225平方毫米),这在人类历史上还是第一次,芯片基于台积电16nm工艺打造,名为WSE——意为晶圆规模引擎,发音为“wise”。在这个芯片里,他们容纳了400,000个处理内核,这些内核都是为AI/ML处理优化的,在15到50kw下有18 GB的SRAM。
当我们第一次听到瓦特数时,反应是“你一定是在开玩笑吧!”
从设计师的角度来看,当前的挑战是:如何处理封装、制造良率(没有一个芯片是完美的)、向芯片传输的功率、功率密度以及从巨大的芯片中散发出来的热量。Cerebras获得了1.11亿美元的风险投资,足够设计他们自己的散热设备和非常规的测试设备和探测站。为了实现这一大胆而非凡的壮举,我想把它称为“晶圆上的超级计算机”,Cerebras的设计师必须在投入大量的设计工作之前,与制造商台积电合作多年,制定出可行的制造和封装技术。最近,HPCA 2019年的一篇论文提出了类似的解决方案。有了这项技术,从传输的角度来看,功能集成将变得更加自然和高效,我们将在接下来讨论这一点。
令人失望但并不令人意外的是,除了说WSE是针对具有特殊张量单元和“sparsity harvesting”的稀sparse linear algebra 进行优化外,Cerebras没有透露任何关于芯片聚合性能( aggregated performance)潜力和功率效率(例如,TOPS/Watt)的进一步信息。在他们的热芯片演示中,他们只是简单地说“它正在工作,并运行几个客户的工作负载”。我相信这些性能数据将在以后用于为这种前所未有的芯片制定定价策略。通过sparsity harvesting,这听起来像是大脑WSE能够消除在矢量和矩阵中带有动态零向量(dynamic zero compression)的无效的计算。
(Process Variation)过程变化
Cerebras的联合创始人Sean Lie提到,虽然制造缺陷问题可以通过冗余和布线绕过后制造来解决,但是Process Variation是他的演讲中没有讨论的另一个棘手问题。当晶体管的特征尺寸继续缩小到7nm (今天)、5 nm (不久的将来)和更低时,这个问题可能尤其突出。
通俗地说,由于掺杂剂扩散波动(dopant diffusion fluctuation)、氧化物厚度的变化(varied oxide thickness)、光刻伪像(lithographic artifact)等因素,在这个尺度上的晶体管是不一样的。
一般来说,为了保证目标性能和良率,芯片设计者必须考虑裸片内部(intra-die variation)的变化,通常是典型掩模版的最大裸片尺寸(~815 mm2)。由于Cerebras的裸片尺寸为46,225 mm2,所有裸片间的变化现在变成了裸片内的变化问题。工作频率可能会受到最慢的晶体管区域的影响,即使较快的区域可以被加速以在更高的频率下运行,如果它们以更细粒度的尺寸从晶片上切割下来的话。为了解决这个缺点,他们可能在其NoC互连内核上采用GALS设计,以允许不同的核心组异步运行。
功率传输(Power Delivery)
此外,如此庞大的芯片将在物理设计空间中面临巨大的挑战。最重要的问题是时钟分配(clock distribution)/时钟偏差(clock skew)和IR下降(drop)。最小化时钟时序(clock timing)偏差以确保所有数字块的同步运行,对于现代电路设计人员来说,这是一项艰巨的任务。具有长线路路径(ong wire paths)的大型芯片只会使这个问题更具挑战性。长导线(Long wires)也会加剧整体电阻,加剧IR下降。管理不善的IR下降可以降低电路的运行速度,因为每个功能单元的电源正在沿着一个长的电阻丝路径向下流动。在最坏的情况下,它可以导致电路故障,如果电压下降到远低于运行标称(operational nominal.)。Cerebras确实提到了他们独特的技术,用垂直的电线在z方向提供和传输能量。假设这是可行的,那么电网或许可以从顶部的“天空”接收到更均匀、更充足的供电电压。
热力
最后,功率密度是一个关键的挑战。请注意,现代处理器的散热机制一度停留在每平方厘米100瓦以下。WSE的功率高达50千瓦,将超过这一限制(108瓦/平方厘米),需要在散热方面进行重大创新。与他们的电力输送系统类似,Cerebras声称安装了z方向的水冷却,同样,使用垂直的水管。有了这些三维齿轮(gears),我确信他们芯片的最终封装将会看起来非常神秘,就像外星技术一样。
通信
那么,为什么他们选择的是一个巨大的芯片,而不是目前的多加速器解决方案或最近出现的基于emerging interposer的Chiplet解决方案呢?潜在的优势是什么?答案很清楚——通信。除了更小和更快的特征尺寸缩放晶体管,即缩放FEOL(FrontEnd-Of-the-Line),小型化还可以缩小BEOL(BackEnd-Of-the-Line,即金属层)以缩短导线长度,虽然速度慢得多。尽管如此,跨裸片的传输是不可避免的,信号将通过跨越PCB上功能裸片的I/O单元驱动。它耗电很大且速度慢。为了解决长延迟问题,部分原因还在于良率和外形尺寸问题,采用多芯片模块(MCM),扇出晶圆级封装(FOWLP或TSMC的InFO)或新兴的芯片封装技术不同程度地缩小传输差距。
不过,Cerebras WSE的设计师将其推向了另一个极端;他们基本上缩小了pcb级的设计,并将其映射到一个大型芯片上。基于此,他们的设计将大部分off-die传输转换为on-die传输网络,从而为神经网络层之间的传输提供了巨大的带宽(100 Pbit/s fabric带宽),从而大大降低了通信延迟和线路功耗。对于神经网络,ML实践者,可以在不离开芯片的情况下,将所有网络层的计算和流映射到WSE的结构中。我相信这是像Cerebras WSE这样的大型芯片的最大动机。
如果你年纪足够大,你就知道早在1980年早期,就有过类似的尝试,那是由传奇人物Gene Amdahl(还记得计算机体系结构101中的Amdahl定律吗?)领导的,他是IBM System/360的首席架构师,他的初创公司Trilogy Systems当时设想了一个晶圆级集成解决方案。资料显示,Trilogy芯片的尺寸大约为2.5英寸x 2.5英寸(4,032平方毫米),并采用耗电的ECL双极晶体管以换取高性能。换句话说,Cerebras WSE的尺寸比上世纪80年代早期的约2.5微米工艺大11.5倍,而台积电16nm中的每个晶体管的面积要小4个数量级。
很高兴看到多年来所有的集体技术进步并将旧的思想提升到现代应用创新的新水平。Cerebras及其合作伙伴台积电(TSMC)已将半导体行业带入一个新时代,单个芯片上的晶体管数量打破了纪录;它确实改变了传统芯片设计的格局。除了计算能力的巨大提升外,长久以来的存储壁垒也可以像传输成本一样以如此大规模的集成被拆除。
这就提出了一些新的研究问题:如何为通用处理器、片上存储器、专用加速器、片上路由器等重新划分片上晶体管资产,以及如何探索不同应用程序类的设计空间。同时,EDA工具,特别是物理设计,必须针对此设计规模进行增强,以实现高效的design closure和sign-off。芯片设计领域的前景将比以往更加有趣。
编后语: 本文作者Hsien-Hsin Sean Lee是IEEE fellow,现在领导Facebook Boston的AI基础设施研究。在此之前,他能分别在TSMC, Georgia Tech, Agere和Intel任职。